504 sem CPU alto, sem fila, sem RDS: quando a infra está verde mas o gateway de pagamento parou de responder
Publicado em 25 de abril de 2026
O incidente que os dashboards não mostraram
Um fintech client reportou Gateway Time-out (erro 504) na página de vendas. O timestamp no screenshot do Cloudflare: 20:25:19 BRT. Fui verificar o que tinha acontecido.
Abri os dashboards. CPU do ASG: 4,1-4,4%. ListenQueue nos três pools PHP-FPM (pool0, pool1, pool2): 0 em todo o período. RDS CPU: média de 1-11%, pico de 11,5% às 20:28. Zero sinais de sobrecarga em qualquer camada da infraestrutura.
Essa é a armadilha clássica do monitoramento de infraestrutura: ele mede o que o servidor está fazendo, não o que o servidor está esperando. I/O bloqueante — uma thread PHP presa esperando resposta de uma API externa — consome zero CPU e zero fila.
Este post é o par do nosso deep-dive sobre CURLOPT_TIMEOUT=0 no gateway de pagamento. Aquele post focou na causa raiz do código. Este foca no ângulo do monitoramento: por que o incidente foi invisível para os alertas padrão, o que os logs mostravam de verdade, e como detectar esse padrão antes que o usuário reporte.
O que os logs mostravam
O nginx tinha três entradas relevantes na janela 20:23-20:27 BRT:
# nginx access log — /vendas, janela do incidente
20:23:09 BRT GET /vendas 499 59.997s
20:25:19 BRT GET /vendas 499 60.001s ← screenshot do cliente
20:26:28 BRT GET /vendas 499 59.998sStatus 499 significa que o cliente encerrou a conexão antes de receber resposta. O Cloudflare tem timeout de 60 segundos — quando o origin não responde em 60s, o Cloudflare fecha a conexão (gerando o 504 no browser) e o nginx registra 499 porque o cliente (Cloudflare) desconectou. O PHP continuou rodando após o 499.
Três requisições, cada uma bloqueada por exatamente 60 segundos. Janela de 4 minutos (20:23-20:26 BRT). Depois disso, o endpoint voltou a responder normalmente em 0,2-3,6s.
Nos logs de debug do PHP-FPM havia uma pista importante: chamadas ao gateway de pagamento com campos como `available_amount`, `waiting_funds_amount` e `transferred_amount` — exatamente o endpoint de consulta de saldo de recebedor. Às 20:26:53 BRT apareceu a resposta do gateway: HTTP 404 com mensagem 'Recipient not found'. O gateway estava com problema.
Por que os monitores não viram nada
A ausência de sinal nos dashboards não foi falha dos monitores — foi uma característica do tipo de falha. Monitorar CPU, memória, ListenQueue e RDS são as métricas certas para detectar sobrecarga de infraestrutura. Mas esse incidente não era sobrecarga: era bloqueio.
ListenQueue = 0 não significa que os workers estão livres
ListenQueue mede quantas requisições estão aguardando um worker PHP-FPM ficar disponível. Com três requisições por 60 segundos cada, a fila ficou praticamente vazia — havia workers disponíveis para aceitar novas conexões. O problema era que os workers aceitos ficavam travados esperando o gateway responder, sem aparecer na fila.
CPU baixa é evidência de I/O bloqueante, não de saúde
Um worker PHP preso em `curl_exec()` aguardando resposta TCP do gateway não consome CPU. O processo fica em estado de espera de I/O — visível via `ps aux` como estado 'S' (sleeping/interruptible). Do ponto de vista do CloudWatch, o servidor está ocioso.
RDS saudável confirma que o problema não era banco
CPU do RDS em 1-11% e sem pico de conexões descartava qualquer hipótese de query lenta ou lock no banco. O travamento estava acontecendo antes da consulta ao banco sequer ser feita — o controller renderizava o saldo da conta (via chamada ao gateway) antes de qualquer query.
# Distribuição de status no nginx durante o incidente (20:20-20:30 BRT)
# Buscar 499 com espaços para evitar falsos positivos (e.g. "4990")
grep ' 499 ' /var/log/nginx/access.log | awk '{print $7, $NF"s"}' | grep '/vendas'
# Verificar workers PHP presos no momento do incidente
curl -s http://localhost/fpm-status?full | grep -E 'state|request uri|request duration' | paste - - -O segundo comando teria mostrado workers em estado 'Reading headers' por dezenas de segundos — esperando a resposta HTTP do gateway. Com três workers presos simultaneamente em requisições de 60 segundos, a capacidade de processamento de novas requisições ao /vendas estava reduzida, mas sem extrapolar o pool total.
A timeline completa
20:22 BRT — /vendas respondendo normalmente (1-3s)
20:23 BRT — gateway começa a travar → primeira requisição bloqueia 60s
20:25 BRT — segunda requisição bloqueia 60s (screenshot do cliente)
20:26 BRT — terceira requisição bloqueia 60s
20:26:53 — gateway retorna HTTP 404 "Recipient not found"
20:27 BRT — /vendas volta a responder (0.2-3.6s)
20:31 BRT — /vendas muito rápido (0.012-0.025s, cache ou dados leves)
20:51 BRT — mais um 499 de 60s em /vendas (problema recorrente no dia)Duração total da janela crítica: aproximadamente 4 minutos. O incidente voltou às 20:51 BRT — o mesmo padrão, confirmando que o problema era recorrente no gateway de pagamento naquele dia.
O que o monitoramento padrão não cobre
A maioria dos setups de monitoramento para aplicações PHP na AWS cobre: CPU da instância, uso de memória, ListenQueue do PHP-FPM, CPU/latência do RDS, e status HTTP 5xx no ALB/CloudFront. Esse conjunto é suficiente para detectar sobrecarga de infraestrutura. Mas há um gap:
Erros 499 com request_time > 10s no nginx não aparecem como 5xx e não disparam alertas de erro padrão. O Cloudflare transforma o 499 em 504 para o usuário final, mas o log do origin registra 499 — e a maioria dos dashboards filtra só 5xx.
A métrica que detecta esse padrão é simples: contagem de status 499 com tempo de resposta acima de um threshold (por exemplo, 30s). Se essa contagem subir, há workers presos em I/O bloqueante — independentemente de CPU e fila estarem verdes.
# CloudWatch Logs Insights — detectar 499 lentos no nginx
fields @timestamp, @message
| filter @message like ' 499 '
| parse @message '* * * * * * * *s' as host, remote, dash, user, time, method, uri, duration
| filter duration > 30
| stats count() as timeout_count by bin(5m)
| sort @timestamp descUm alerta de '3 ou mais 499 com request_time > 30s em 5 minutos' no endpoint /vendas teria disparado às 20:23 BRT — 2 minutos antes do screenshot do cliente chegar.
A causa raiz e o fix
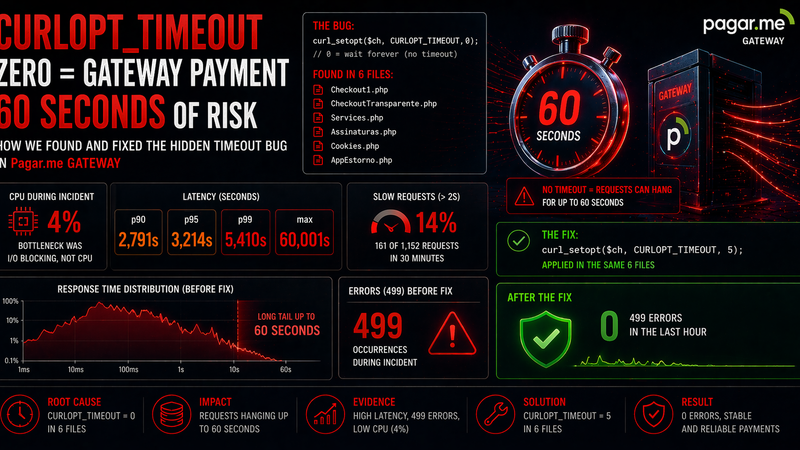
O controller de vendas fazia uma chamada síncrona ao gateway de pagamento para buscar saldo de recebedor durante o render da página. O método usado para todas as chamadas ao gateway tinha `CURLOPT_TIMEOUT => 0` — que no cURL não significa 'sem configuração', significa 'esperar indefinidamente'.
O fix aplicado foi adicionar timeout explícito no método central que todas as chamadas usavam, cobrindo de uma vez todos os endpoints do gateway:
// Antes — timeout infinito em todas as chamadas ao gateway
CURLOPT_TIMEOUT => 0,
// Depois — fail fast em 8s, reconectar em 5s
CURLOPT_TIMEOUT => 8,
CURLOPT_CONNECTTIMEOUT => 5,Resultado imediato após o deploy: os 499 de 60 segundos em /vendas zeraram. O p99 de latência voltou a menos de 1 segundo. A recomendação complementar ao time de desenvolvimento foi adicionar fallback no controller: se o gateway não responder em 8s, renderizar a página com saldo como '--' (em vez de travar o request inteiro).
Lição operacional
Infraestrutura verde não significa aplicação saudável. CPU baixa, fila vazia e banco estável são condições necessárias para saúde, mas não suficientes. Um controller que faz chamada síncrona a serviço externo sem timeout configurado é um vetor de indisponibilidade que nenhum monitor de infraestrutura vai detectar — porque o problema não está na infraestrutura.
O monitoramento correto para esse padrão opera na camada de aplicação: contagem de 499 com request_time alto, percentis de latência por endpoint, e alertas de timeout em chamadas a APIs externas. Sem isso, o primeiro sinal de problema chega via screenshot do usuário — não via alerta.