504但CPU不高、队列为空、RDS正常:当基础设施全绿而支付网关停止响应
发布于 2026年4月25日
仪表盘没有显示的事故
一个金融科技客户报告了销售页面出现了网关超时(504错误)。Cloudflare截图上的时间戳显示为20:25:19。我去查看发生了什么。
我打开了仪表盘。ASG CPU:4.1-4.4%。三个PHP-FPM池(pool0、pool1、pool2)的ListenQueue在整个期间全部为0。RDS CPU:平均1-11%,峰值11.5%。基础设施各层均无任何过载迹象。
这是基础设施监控的经典陷阱:它测量的是服务器正在做什么,而不是服务器在等待什么。阻塞I/O——一个PHP线程卡在等待外部API响应——消耗零CPU,占用零队列。
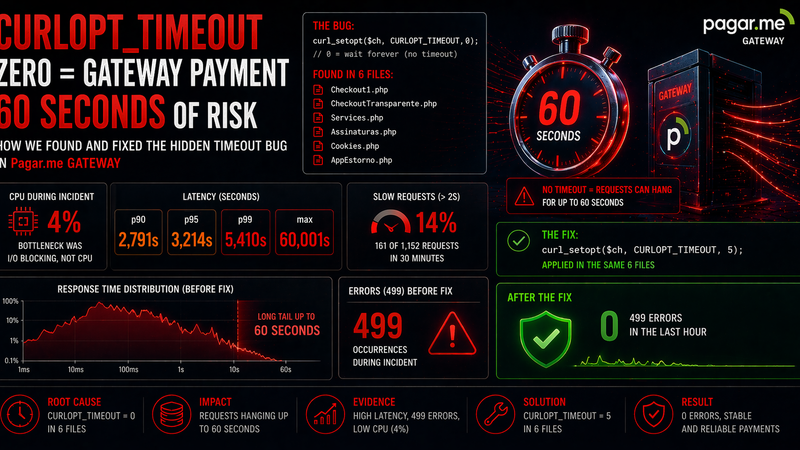
本文是我们关于支付网关中CURLOPT_TIMEOUT=0问题深度分析的配套文章。那篇文章聚焦于代码层面的根本原因。本文聚焦于监控角度:为什么这个事故对标准告警不可见,日志实际显示了什么,以及如何在用户报告之前检测到这种模式。
日志显示的内容
Nginx在20:23-20:27的时间窗口内有三条相关记录:
# nginx access log — /sales页面,事故窗口
20:23:09 GET /sales 499 59.997s
20:25:19 GET /sales 499 60.001s ← 客户截图时刻
20:26:28 GET /sales 499 59.998s状态499表示客户端在收到响应之前关闭了连接。Cloudflare有60秒的超时——当源站60秒内没有响应时,Cloudflare关闭连接(在浏览器中产生504),nginx记录499因为客户端(Cloudflare)已断开。PHP在499之后继续运行。
三个请求,每个精确阻塞60秒。 4分钟的时间窗口(20:23-20:26)。此后,接口恢复正常,响应时间为0.2-3.6秒。
在PHP-FPM的调试日志中有一个重要线索:对支付网关的调用包含`available_amount`、`waiting_funds_amount`和`transferred_amount`等字段——正好是收款方余额查询接口。20:26:53,出现了网关的响应:HTTP 404,消息为'Recipient not found'。支付网关出现了问题。
为什么监控什么都没看到
仪表盘上没有信号并不是监控的失败——而是这种故障类型的特性。监控CPU、内存、ListenQueue和RDS是检测基础设施过载的正确指标。但这个事故不是过载:而是阻塞。
ListenQueue = 0并不意味着workers空闲
ListenQueue测量的是等待PHP-FPM worker空闲的请求数量。三个请求各持续60秒,队列几乎保持为空——有worker可以接受新连接。问题在于被接受的worker卡在等待网关响应,而不出现在队列中。
CPU低是阻塞I/O的证据,而非健康的证明
一个PHP worker卡在curl_exec()等待网关TCP响应时不消耗CPU。该进程保持在I/O等待状态——通过ps aux可以看到状态为'S'(睡眠/可中断)。从CloudWatch的角度来看,服务器处于空闲状态。
RDS健康确认问题不在数据库
RDS CPU在1-11%且无连接峰值,排除了慢查询或数据库锁的任何假设。阻塞发生在任何数据库查询执行之前——控制器在任何查询运行之前就通过网关调用渲染账户余额。
# 事故期间nginx状态分布(20:20-20:30)
# 使用空格避免误匹配(如"4990")
grep ' 499 ' /var/log/nginx/access.log | awk '{print $7, $NF"s"}' | grep '/sales'
# 查看事故时刻被卡住的PHP workers
curl -s http://localhost/fpm-status?full | grep -E 'state|request uri|request duration' | paste - - -第二条命令会显示worker处于'Reading headers'状态长达数十秒——等待网关的HTTP响应。三个worker同时卡在60秒请求上,处理新请求的能力降低了,但没有超出总pool的容量。
完整时间线
20:22 — /sales正常响应(1-3秒)
20:23 — 网关开始挂起 → 第一个请求阻塞60秒
20:25 — 第二个请求阻塞60秒(客户截图时刻)
20:26 — 第三个请求阻塞60秒
20:26:53 — 网关返回HTTP 404 "Recipient not found"
20:27 — /sales恢复正常(0.2-3.6秒)
20:31 — /sales响应非常快(0.012-0.025秒,缓存或轻量数据)
20:51 — /sales再次出现60秒499(当天问题反复出现)关键窗口总持续时间:约4分钟。事故在20:51再次发生——相同的模式,确认支付网关当天存在反复出现的问题。
标准监控的盲区
大多数AWS上PHP应用的监控配置涵盖:实例CPU、内存使用、PHP-FPM ListenQueue、RDS CPU/延迟,以及ALB/CloudFront层的5xx HTTP状态。这足以检测基础设施过载。但存在一个盲区:
nginx中request_time > 10s的499错误不显示为5xx,不触发标准错误告警。Cloudflare将499转换为用户看到的504,但源站日志记录499——大多数仪表盘只过滤5xx。
检测这种模式的指标很简单:响应时间超过阈值(例如30秒)的499状态计数。如果该计数上升,就有worker卡在阻塞I/O中——无论CPU和队列是否显示绿色。
# CloudWatch Logs Insights — 检测nginx中的慢速499
fields @timestamp, @message
| filter @message like ' 499 '
| parse @message '* * * * * * * *s' as host, remote, dash, user, time, method, uri, duration
| filter duration > 30
| stats count() as timeout_count by bin(5m)
| sort @timestamp desc在/sales接口上设置'5分钟内3个以上request_time > 30秒的499'告警,会在20:23触发——比客户截图到达早2分钟。
根本原因与修复
销售控制器在页面渲染时向支付网关发起同步调用以获取收款方余额。所有网关调用使用的方法设置了`CURLOPT_TIMEOUT => 0`——在cURL中这不意味着'未配置',而是'无限期等待'。
应用的修复是在所有调用共用的核心方法上添加明确的超时,一次性覆盖所有网关接口:
// 修复前——所有网关调用无限超时
CURLOPT_TIMEOUT => 0,
// 修复后——8秒快速失败,5秒连接超时
CURLOPT_TIMEOUT => 8,
CURLOPT_CONNECTTIMEOUT => 5,部署后立竿见影:/sales上的60秒499降至零。延迟p99恢复到1秒以下。对开发团队的补充建议是在控制器中添加降级处理:如果网关8秒内没有响应,渲染余额显示为'--'的页面,而不是阻塞整个请求。
运维经验
基础设施显示绿色不等于应用健康。CPU低、队列空、数据库稳定是健康的必要条件,但不是充分条件。一个在没有配置超时的情况下对外部服务进行同步调用的控制器,是任何基础设施监控都无法检测到的可用性风险——因为问题不在基础设施。
针对这种模式的正确监控在应用层运作:高request_time的499计数、按接口的延迟百分位,以及外部API调用的超时告警。没有这些,问题的第一个信号通过用户截图到达——而不是通过告警。