每日168,551次请求导致PHP-FPM饱和:用nginx srcache + Valkey via stunnel解决
发布于 2026年3月31日
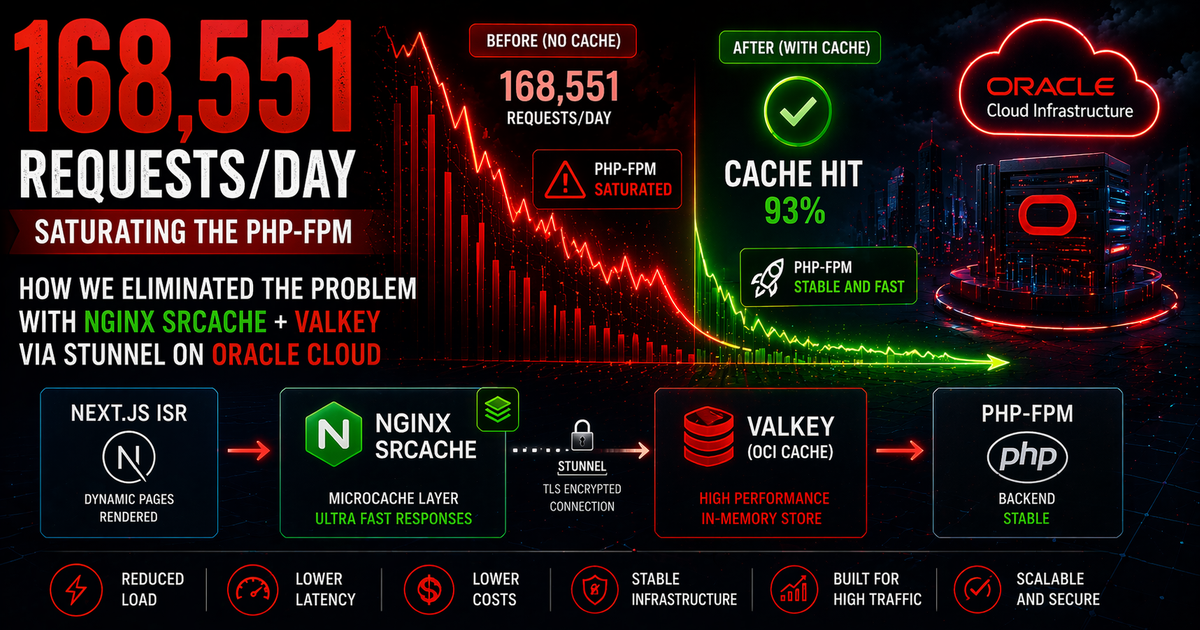
问题:ISR级联导致的大规模PHP-FPM饱和
该门户使用带有ISR(增量静态再生)的Next.js来提供拥有数万个词条的词汇表服务。`revalidate: 60`的配置指示Next.js每60秒重新生成每个页面——这意味着词汇表的36,508个页面每分钟都会向内部WordPress API发起一轮持续不断的请求。
对内部端点的访问模式如下:
GET /wp-json/api/v1/glossary?per_page=100&page=1
GET /wp-json/api/v1/glossary?per_page=100&page=2
...
GET /wp-json/api/v1/glossary?per_page=100&page=36508在`revalidate: 60`的情况下,这36,508个请求的完整循环每分钟重复一次。流量高峰时,仅这个端点每天就产生168,551次请求。在只有150至201个PHP-FPM Worker可用的情况下,每个周期不到60秒Socket就会返回`Resource temporarily unavailable`错误。这些突发流量持续1至2分钟,每隔60至90分钟重复一次。
此前尝试了并发数为10的p-queue,但没有效果:面对36k个页面和60秒revalidate,队列在下一个周期开始前永远无法清空。请求总量不会下降——只是并发峰值被平滑了。
解决方案:nginx srcache + Valkey via stunnel
缓存架构分三层构建,全部运行在同一台主机(OCI虚拟机)上:
Next.js ISR → nginx(OpenResty)搭配srcache → stunnel(127.0.0.1:6379)→ OCI Cache Valkey(TLS)
带有srcache模块的nginx在请求到达PHP-FPM之前拦截对/wp-json/的请求。如果响应已在Valkey中,则直接返回——PHP完全不被调用。若缓存未命中,则调用PHP,响应存入Valkey,后续相同请求从缓存提供服务。
为什么使用stunnel?
OCI Cache要求TLS连接。OpenResty的redis_pass和redis2_pass模块不原生支持TLS——它们以明文方式连接Redis。解决方案是stunnel作为本地代理:nginx连接到127.0.0.1:6379(明文),stunnel加密后通过TLS转发到OCI Cache的FQDN端口6379。
stunnel配置
/etc/stunnel/redis-oci.conf
[redis-oci]
client = yes
accept = 127.0.0.1:6379
connect = <oci-cache-fqdn>.redis.sa-saopaulo-1.oci.oraclecloud.com:6379
verifyChain = no将其设置为持久化systemd服务:
systemctl enable stunnel@redis-oci --now配置nginx之前先测试连通性:
redis-cli -h 127.0.0.1 -p 6379 PING # 应返回PONGnginx srcache配置(OpenResty)
关键在于使用redis.conf而非wpfc.conf。两者的根本区别:
wpfc.conf(fastcgi_cache):对$query_string有跳过逻辑——带有?per_page=100&page=N的请求不会被缓存。
redis.conf(srcache):对查询字符串没有跳过逻辑——每个?per_page=100&page=N都会被单独缓存。这正是ISR所需要的行为。
/wp-json/的srcache配置块:
location ^~ /wp-json/ {
set $key "$scheme$host$request_uri";
set $escaped_key $key;
srcache_fetch_skip $skip_cache;
srcache_store_skip $skip_cache;
srcache_response_cache_control off;
srcache_fetch GET /redis-fetch $key;
srcache_store PUT /redis-store key=$escaped_key;
more_set_headers 'X-SRCache-Fetch-Status $srcache_fetch_status';
more_set_headers 'X-SRCache-Store-Status $srcache_store_status';
fastcgi_pass php;
include fastcgi_params;
}Redis upstream指向本地stunnel:
upstream redis {
server 127.0.0.1:6379;
keepalive 512;
}关键陷阱:try_files会破坏一切
/wp-json/块的第一个版本使用了`try_files $uri $uri/ /index.php?$args`——这是WordPress配置中常见的模式。这导致所有对/wp-json/的GET请求都返回301重定向到/:调用链是try_files → 内部重定向到/index.php → redis.conf中定义的`location = /index.php { return 301 /; }`。
永远不要在不提供静态文件的location中使用try_files。对于/wp-json/,直接使用fastcgi_pass。
陷阱:用curl -sI测试缓存
验证期间,使用`curl -sI`(HEAD请求)测试时总是返回`X-SRCache-Store-Status: BYPASS`——响应中没有body,srcache什么都不存储。正确的测试方式是使用GET:
# 第一次请求:MISS(调用PHP,响应被存储)
curl -s https://portal.example.com/wp-json/api/v1/glossary?per_page=100&page=1 \
-o /dev/null -w '%{http_code} %header{X-SRCache-Fetch-Status}'
# 200 MISS
# 第二次请求:HIT(Valkey命中,PHP未被调用)
# 200 HITWP Redis对象缓存使用同一数据库
WordPress也配置了Redis Object Cache插件,通过stunnel指向同一个Valkey实例,使用数据库0——与nginx srcache相同的数据库。
// wp-config.php
define( 'WP_REDIS_HOST', '127.0.0.1' );
define( 'WP_REDIS_PORT', 6379 );
define( 'WP_REDIS_DATABASE', 0 );共享数据库0的决定是有意为之:在紧急情况下,通过WP Redis插件执行FLUSHDB可以同时清除对象缓存和nginx缓存——当需要立即完全清除缓存时,这是理想的行为。
OCI网络配置
WordPress VM和OCI Cache集群位于不同的子网中。需要在缓存集群的安全列表中添加入站规则,允许来自VM子网的TCP 6379流量:
# VM子网(公有):10.1.0.0/24
# OCI Cache子网(私有):10.1.1.0/24
# 添加的规则:来自10.1.0.0/24的入站TCP 6379重要提示:始终使用OCI Cache的FQDN,不要使用私有IP。OCI托管服务的私有IP可能会变更,FQDN由服务自动更新。
结果
配置完成后,第一天缓存命中率就达到了93%。PHP-FPM不再饱和。每天168,551次请求仍然到达nginx——但其中93%由Valkey直接响应,不经过PHP。
X-SRCache-Fetch-Status: HIT → Valkey响应,PHP未被调用
X-SRCache-Fetch-Status: MISS → 首次请求,PHP被调用,响应已缓存
X-SRCache-Store-Status: BYPASS → 带认证Cookie的请求,不缓存(正确行为)
问题的根本修复在于代码层面——将Next.js的revalidate从60秒增加到3600秒可将每日约168k次请求减少到约36k次。但在开发团队实施之前,基础设施已能在不降级的情况下承载负载。
技术栈总结
OpenResty(nginx + srcache + redis2模块) — 在PHP之前拦截/wp-json/请求
stunnel — 本地TLS代理(127.0.0.1:6379 → OCI Cache FQDN:6379)
OCI Cache(Valkey 7.2) — 托管Redis兼容集群,每月$19,sa-saopaulo-1区域
WP Redis对象缓存 — 数据库0,同一集群,统一缓存失效
缓存基础设施总成本:每月$19。PHP-FPM和CPU的节省:无法直接量化,但避免了在找到该解决方案之前正在考虑的OKE集群水平扩展。
